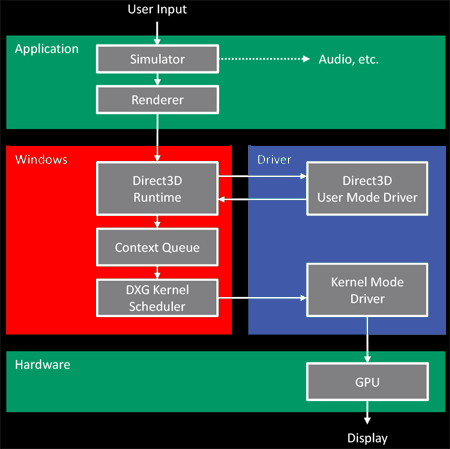
DXG Kernel Scheduler
My už jsme si řekli, že DirectX může v jednom okamžiku využívat více než jedna aplikace. Můžeme například hrát současně dvě hry ve dvou různých oknech a tak se nám do DirectX pipeline dostávají Draw Calls z dvou různých aplikací. Všechny tyto Draw Calls jsou přeměněny na Command Buffery a všechny také skončí v zásobníku Context Queue.
Úlohou DXG Kernel Scheduler (plánovač) je rozhodnout, jaké Command Buffery a z jaké aplikace budou v pipeline pokračovat dále, a které budou muset počkat. Nejčastěji se plánovač se rozhoduje na základě časových intervalů, kdy střídavě každou chvilku pustí dále Command Buffery z jiné aplikace. Když se plánovač rozhodne, který Command Buffer bude mít přednost, vyzvedne ho z našeho zásobníků Context Queue a odešle jej do další zastávky se jménem Kernel Mode Driver.
Kernel Mode Driver (KMD)
Kernel Mode Driver je poslední zastávkou DirectX pipeline a podobně jako User Mode Driver se jedná o knihovnu, která je dodávána společně s ovladači výrobcem grafického čipu. KMD je právě ta část DirectX pipeline, která jako jediná fyzicky komunikuje s grafickou kartou. Pomocí KMD je tedy možné všechny Command Buffery konečně zaslat na grafickou kartu. Nepředbíhejme ale, samotné odesílání Command Bufferů není to jediné, co má KMD na práci.
Command Buffery totiž mohou obsahovat také odkazy (adresy) na umístění zdrojů (třeba textur) v grafické paměti GPU. To už víme z popisu práce UMD, který je právě odpovědný za alokaci (umístění) nových zdrojů ve VRAM. Problémem ale je samotná správa paměti (Fyziská správa paměti). Za tuto správu je odpovědný správce paměti, který ale může časem některé alokace zdrojů ve VRAM přemístit nebo dokonce úplně odstranit. Adresní odkazy na zdroje, které jsou uvedené v Command Buffers tak nemusí být platné a pokud by takový „vadný“ Command Buffer s neplatnou adresou byl odeslán na grafickou kartu, mohlo by být zle.
KMD tedy musí prozkoumat každý Command Buffer a pátrat, zda v něm uvedené adresy umístění zdrojů jsou platné, či nikoliv. Pokud nejsou, celý Command Buffer musí čekat na zajištění nápravy (zjištění správné aktuální adresy a její zapsání, nebo novou alokaci zdroje a zapsání její adresy). Teprve až se KMD přesvědčí, že je vše v pořádku, odešle příslušný Command Buffer na zpracování grafické kartě. Command Buffery jsou na grafickou kartu zasílány jakýmsi dopravníkem s názvem Command Queue.

Jak můžete vidět, cesta DirextX pipeline je opravdu dlouhá a klikatá. Než naše příkazy na vykreslení (Draw Calls) doputují přes toto potrubí do grafické karty ve formě Command Buffers uplyne nezdravě dlouho času a také procesor, který to má vše pod taktovkou, se trochu více zapotí (API Overhead).
Veškerý „provoz“ v pipeline je výsostně sériový. Příkazy na vykreslení procházejí touto pipeline tedy pěkně jeden za druhým a proto ani aplikace (hra) nemůže využít více vláken (jader) procesoru pro vytváření většího počtu Draw Calls zasílaných do DirectX. Vytváření a odesílání Draw Calls je tedy v herní smyčce vyhrazeno jediné vlákno (Render thread), které v tom horším případě může konzumovat prostředky až celého příslušného jádra procesoru.
Pokud se nám pak na některém jádru CPU k režii aplikace a jejího renderovacího vlákna přičte také režie samotného DirectX, dostáváme se do velkých problémů. Procesor se stává reálnou brzdou celé herní smyčky a to i přes to, že většina volných zdrojů CPU (ve zbylých jádrech) je nevyužito. Procesor přestane stíhat připravovat nové snímky pro grafickou kartu a snímková frekvence hry jde nezvratně dolů (CPU Bound).
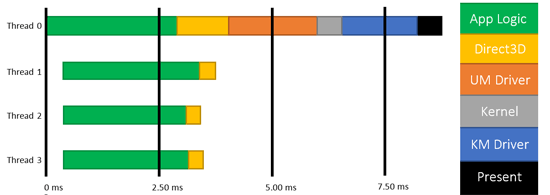
Nerovnoměrná distribuce práce mezi jednotlivá vlákna (nebo jádra) procesoru a vysoká režie 3D API byla tím hlavním podnětem dělat věci trochu jinak. Proto vzniklo 3D API nové generace Mantle a jeho pozdější následovníci DirectX 12, Vulkan a Metal.